یادگیری ماشین (Machine Learning) چیست و چرا باید یاد بگیریم؟ (راهنمای جامع و کاربردی)
مقدمه
به آینده خوش آمدید. جایی که کامپیوترها قادر به دیدن، شنیدن و یادگیری هستند. خدماتی که امروز به کمک یادگیری ماشین به ما عرضه میشوند، چند دهۀ قبل برای انسان مثل رؤیا بودند و اثر این رؤیاپردازی را فقط میتوانستیم در فیلمهای علمیتخیلی ببینیم. بهعنوان یک انسان که در "آینده" زندگی میکند، چقدر با تعریف ماشین لرنینگ آشنا هستید؟ زمانی که آرتور ساموئل برای اولینبار اصطلاح یادگیری ماشین را در سال 1959 به کار برد، آن را به این صورت تعریف کرد: یادگیری ماشین یک زمینۀ مطالعاتی است که به رایانهها توانایی یادگیری بدون برنامهنویسی صریح (Explicit Programming) را میدهد. آرتور ساموئل (1990-1901) از مهمترین پیشگامان هوش مصنوعی و بازیهای رایانهای بود و به نظر میرسد تعریفی که ارائه داده، هنوز که هنوز است بهترین تعریف برای یادگیری ماشین است. به طورکلی میتوان گفت یادگیری ماشین زیرمجموعهای از هوش مصنوعی است که به ماشینها اجازه میدهد بدون تجزیهوتحلیل از تجربیات خود درس بگیرند و خود را بدون انجام هیچگونه کدنویسی جدید بهبود بخشند. برای مثال، وقتی از فروشگاههای اینترنتی خرید میکنید، قسمت جستجوی مرتبط (Related Search) یکی از قابلیتهای ماشین لرنینگ است. همان قسمتی که کالاهایی را به شما پیشنهاد میدهد و میگوید افرادی که این کالای بهخصوص را خریدهاند، اینها را نیز مشاهده کردهاند. با ادامۀ مطالعۀ این مقاله ممکن است سؤالات یا ابهاماتی برایتان ایجاد شود. این موضوع کاملاً طبیعی است؛ برای همین اصلاً نگران نباشید. چون با پیش رفتن و ادامه دادن، کمکم خلأهای ذهنیتان پر میشود و نگرش خوبی نسبت به مفهوم ماشین لرنینگ پیدا میکنید.
فهرست مطالب
یادگیری ماشین چه تفاوتی با برنامهنویسی سنتی دارد؟
در برنامهنویسی سنتی، ما دادههای ورودی و یک برنامه را برای تولید یک خروجی مشخص به ماشین وارد میکنیم. اما در اغلب فرایندهای یادگیری ماشین، دادههای ورودی به همراه خروجی در طول مرحلۀ یادگیری (Learning Phase) وارد دستگاه میشوند و در نتیجه یک برنامه تولید میشود.
از این طریق، یادگیری ماشین، ماشینها را در رفتار و تصمیمات خود شبیه به انسان میکند و به آنها توانایی یادگیری و توسعۀ برنامههای خود را میدهد. این کار با حداقل دخالت انسان انجام میشود. یعنی بدون نیاز به کدنویسی و برنامهنویسی صریح!
این روند یادگیری کاملاً خودکار و اتوماتیک است و بر اساس تجربیات ماشینها در طول فرایند بهبود مییابد. به این صورت که دادههای باکیفیت خوب (Good Quality Data) به ماشینها تغذیه میشوند و از الگوریتمهای مختلف برای ساخت مدلهای ML برای آموزش ماشینها استفاده میشود. انتخاب الگوریتم بستگی به نوع دادههای موجود و نوع فعالیتهایی دارد که باید به صورت خودکار انجام شوند.
چرا باید ماشین لرنینگ را یاد بگیریم؟
امروزه در تمامی کشورهای دنیا توجه ویژهای به یادگیری ماشین میشود. علت این موضوع کاملاً مشخص است: یادگیری ماشین میتواند بسیاری از وظایف را بهصورت خودکار انجام دهد. مخصوصاً وظایفی که فقط انسانها میتوانند با هوش ذاتی خود انجام دهند.
با کمک ماشین لرنینگ مشاغل میتوانند بخش زیادی از کارهای معمول خود را بهصورت خودکار انجام دهند. ML با ایجاد مدلهایی برای تجزیهوتحلیل دادهها بهسرعت پیشروی فرایندهای آنالیزی یا آماری کمک بزرگی میکند، چرا که صنایع مختلف برای بهینهسازی عملیات خود و اتخاذ تصمیمات هوشمند به حجم وسیعی از دادهها وابسته هستند. اینجاست که Machine Learning وارد عمل میشود و به ایجاد مدلهایی کمک میکند که میتوانند حجم زیادی از دادههای پیچیده را پردازش و آنالیز کنند و نتایج دقیقی را ارائه دهند.
خوبی این مدلها این است که دقیق و مقیاسپذیر هستند و با زمان برگشت (Turnaround Time) کمتری کار میکنند. با ایجاد چنین مدلهای دقیقی، یادگیری ماشین میتواند فرصتهای سودآوری را برای مشاغل به ارمغان بیاورد و از خطرات ناشناخته جلوگیری کند.
در این راستا، ML از آن جهت اهمیت دارد که به شرکتها نمایی از رفتار مشتریان و الگوهای عملیاتی کسب و کار ارائه میدهد و از توسعۀ محصولات جدید پشتیبانی میکند. بسیاری از شرکتهای پیشروی امروزی مانند فیسبوک، گوگل و اوبر، یادگیری ماشین را بخش اصلی عملیات روزانۀ خود میدانند.
برخی اصطلاحات متداول در یادگیری ماشین
بررسی مباحث مربوط به ماشین لرنینگ بدون اطلاع از تعاریف مهم آن غیرممکن است. از این رو، قبل از ادامۀ مقاله بهتر است نگاهی به این اصطلاحات متداول و مفاهیم آنها بیندازیم.
مجموعه داده (Data set)
منظور از دیتاست، تعدادی از اطلاعات با ویژگیهای معین است که در یک حیطۀ مشخص جمعآوری شده است. به عبارت دیگر، مجموعه داده به مجموعهای از دادهها گفته می شود که با موضوعیتی یکسان، برای انجام تحلیلها و پروژههای دادهکاوی استفاده میشوند.
آموزش (Training)
یک الگوریتم، مجموعهای از دادهها را که بهعنوان دادههای آموزشی معروف هستند، به عنوان ورودی میگیرد. الگوریتم یادگیری الگوهایی را در دادههای ورودی پیدا میکند و با استفاده از این الگوها، مدل را برای نتایج مورد انتظار (Target) آموزش میدهد. خروجی فرایند آموزش مدل یادگیری ماشین است.
مدل (Model)
منظور از مدل که ممکن است بهعنوان فرضیه (Hypothesis) نیز شناخته شود، نمایش ریاضی از یک فرایند در دنیای واقعی است. یک مدل ماشین لرنینگ از الگوریتم یادگیری ماشین به همراه دادههای آموزشی تشکیل میشود.
پیشبینی (Prediction)
هنگامی که مدل یادگیری ماشین آماده شد، میتوان دادههای ورودی را به سیستم تغذیه کرد تا خروجی پیشبینی شده را ارائه دهد.
هدف یا برچسب (Traget or Label)
مقداری که مدل یادگیری ماشین باید آن را پیشبینی کند، هدف یا برچسب نامیده میشود.
ویژگی (Feature)
ویژگی یک خاصیت یا پارامتر قابلاندازهگیری مجموعهداده (Data Set) است.
بردار ویژگی (Feature Vector)
مجموعهای از چندین ویژگی عددی است. از بردار ویژگی بهعنوان ورودی برای مدل یادگیری ماشین استفاده میشود. اگر این بردار نباشد، اهداف آموزشی و پیشبینی در مدل به دست نمیآید.
برازش بیش از حد (Overfitting)
وقتی که حجم عظیمی از دادهها یک مدل یادگیری ماشین را آموزش میدهند، سیستم تمایل دارد از نویزها و ورودیهای نادرستی که بین دادهها وجود دارد، درس بگیرد. در این حالت مدل نمیتواند دادهها را بهدرستی تشخیص دهد.
برازش کمتر از حد (Underfitting)
زمانی که مدل نتواند روند اصلی را در دادههای ورودی رمزگشایی کند، Underfitting رخ داده است. این اتفاق دقت مدل ML را از بین میبرد. به عبارت سادهتر، مدل یا الگوریتم به اندازۀ کافی برای دادهها مناسب نیست.
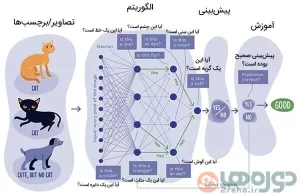
مراحل هفتگانه یادگیری ماشین
هر فرایند یادگیری ماشین از ابتدا تا انتها به هفت مرحلۀ کلی تشکیل میشود که در ادامه هر یک را شرح میدهیم.
مرحلۀ اول: جمعآوری داده
جمعآوری داده ممکن است بسته به هدفی که هر فرد یا سازمان دارد، بسیار متنوع باشد. حتی هر فرد یا سازمان ممکن است مجموعه دادههای مورد نظر خود را از راههای مختلفی تهیه کند. از تهیۀ دستی و گزارشگیریهای میدانی گرفته تا گردآوری اتوماتیک دیتا از فضای اینترنت.
جدای از این تفاوتها، این بسیار مهم است که ما بدانیم به دنبال چه هستیم و اصلاً چرا قرار است الگوریتمهای یادگیری ماشین را آموزش دهیم. کیفیت و کمیت دادههایی که جمعآوری میکنید، به طور مستقیم تعیین میکند که مدل پیشبینی شما چقدر دقیق باشد.
مرحلۀ دوم: آمادهسازی دادهها
معمولاً وقتی دادههایی را در یک سازمان جمعآوری میکنیم، این امکان وجود دارد که تناقضات و ناسازگاریهایی مانند ورودیهای نادرست یا حذف شده وجود داشته باشد. از این رو لازم است با مجتمع کردن دادهها، بازسازی دادههای گم شده، استانداردسازی یا یک شکل کردن دیتاست و نرمالسازی دادهها در جهت رفع این مشکلات اقدام کنیم.
نکتۀ مهمی که وجود دارد، این است که دادهها کاملاً باید تصادفی یا به اصطلاح Randomize شده باشند. این کار هرگونه اثری از هر نظم خاصی را در دادههای ما از بین میبرد، چرا که ما نمیخواهیم نظم و ترتیب دادهها بر آموختههای سیستم تأثیر بگذارد.
مرحلۀ سوم: انتخاب مدل
گام بعدی در گردش کار ما، انتخاب مدل برای دادههای آماده شده است. مدلهای زیادی وجود دارد که محققان و دانشمندان داده در طول سالها ایجاد کردهاند. برخی برای دادههای تصویری یا دادههای عددی مجزا مناسب هستند، برخی دیگر نیز برای دادههای دنبالهای (مانند متن یا موسیقی). مسئلهی اصلی برای انتخاب مدل، نوع دادههای شماست.
مرحلۀ چهارم: آموزش
حالا زمان آن رسیده که به مرحلۀ اصلی یادگیری ماشین، یعنی آموزش بپردازیم. در این مرحله، ما از دادههای خود برای افزایش تدریجی توانایی مدلی که انتخاب کردهایم، استفاده میکنیم. برای مثال میتوان فرمول خط راست را مثال زد.
فرمول یک خط راست از فرمول زیر به دست می آید:
y = m*x+b
در این رابطه، m شیب خط، b عرض از مبدأ و x و y نیز به ترتیب ورودی و خروجی ما هستند. مقادیری که ما برای آموزش در اختیار داریم، m و b هستند. هیچ راه دیگری برای تأثیر بر موقعیت خط وجود ندارد. چرا که در این مرحله نمیتوانیم با متغیرهای دیگر که ورودی و خروجی ما هستند، کاری داشته باشیم.
فرایند آموزش، شامل مقداردهی تصادفی به m و b و تلاش برای پیشبینی خروجی با این مقادیر است. این روند آنقدر تکرار میشود تا در نهایت به خط نهایی (مدل) نزدیک شویم. اینجا الگوریتم چه چیزی را باید یاد بگیرد؟ بله، m و b را. برای همین است که نام فرایند کلی یادگیری ماشین است. در ادامۀ مقاله در مورد آموزش و انواع آن بیشتر صحبت میکنیم.
مرحلۀ پنجم: ارزیابی
پس از اتمام آموزش، وقت آن است که ببینیم آیا مدلی که در نهایت ساخته شده خوب است یا خیر. این اطمینانسنجی با ارزیابی یا Evaluation انجام میگیرد. در این مرحله لازم است ما از یک سری دیتا که قبلاً استفاده نشدهاند، یعنی در مرحلۀ دوم کنار گذاشته شدهاند استفاده کنیم تا دقت و صحت مدل را بسنجیم.
بنابراین ارزیابی به ما این امکان را میدهد که مدل حاصل را در برابر دادههایی که هرگز برای آموزش استفاده نشدهاند، آزمایش کنیم و ببینیم آیا واقعاً جواب میدهد یا خیر؟ این مرحله به ما اجازه میدهد تا ببینیم مدل چگونه میتواند در برابر دادههایی که هنوز ندیده است، عمل کند. به عبارت دیگر، نحوه عملکرد مدل در دنیای واقعی سنجیده میشود.
حساسیت (Sensitivity) و تشخیصپذیری (Specificity) دو شاخص مهم برای ارزیابی آماری عملکرد نتایج آزمونهای طبقهبندی باینری (دودویی یا دوحالته) هستند. اگر در آمار سررشتهای داشته باشید، میدانید که این دو شاخص بهعنوان توابع طبقهبندی شناخته میشوند.
اگر بتوانیم دادهها را به دو گروه مثبت و منفی تقسیم کنیم، عملکرد نتایج یک الگوریتم که اطلاعات را به مثبت و منفی تقسیم میکند، با استفاده از شاخصهای حساسیت و تشخیصپذیری قابلیت اندازهگیری و توصیف خواهد داشت.
لازم به ذکر است که بعضاً ممکن است در منابع مختلف، تشخیصپذیری را دقت (Precision) و حساسیت را صحت (Recall) نیز بنامند. خب، حالا که دادهها را به دو گروه مثبت و منفی تقسیم کردیم، نتایج را به چهار صورت زیر خواهیم داشت:
- مثبت صحیح
- مثبت کاذب
- منفی صحیح
- منفی کاذب
مثلاً در بخش امنیت فرودگاه وقتی ابزارهای عادی مثل کلید و سکه اشتباهاً اسلحه تشخیص داده شوند و ماشین صدای "بیپ" ایجاد کند، یک مثبت کاذب داریم. مثبت این بود که تشخیص اسلحه صورت بگیرد. یعنی معنی مثبت این بود که ما اسلحه داریم. حالآنکه اینجا مثبتی که دستگاه اعلام کرده صحیح نیست و الگوریتم نیاز به تنظیمات مجدد دارد.
با یک مثال دیگر موافقید؟ در بحث کنترل کیفیت، یک مثبت کاذب وقتی اتفاق میافتد که محصول با کیفیت خوب مردود میشود و یک منفی کاذب هنگامی اتفاق میافتد که محصول بیکیفیت توسط ماشین مورد قبول اعلام میشود.
ما همواره به دنبال مثبت صحیح و منفی صحیح هستیم. یعنی در آزمونهای طبقهبندی باینری غیر از این دو حالت خطا محسوب میشوند.
مرحلۀ ششم: تنظیم پارامترها
هنگامی که ارزیابی انجام شد، ممکن است بخواهید ببینید آیا میتوانید آموزش خود را ارتقا دهید یا خیر؟ ما میتوانیم این کار را با تنظیم پارامترهای خود انجام دهیم. چند پارامتر وجود داشت که ما به طور ضمنی هنگام آموزش تصور میکردیم و اکنون زمان خوبی برای بازگشت به عقب و آزمایش این مفروضات و امتحان مقادیر دیگر است.
در واقع اینجا میتوان پارامترهای مرحلۀ آموزش را بازنگری کرد. هنگامی که از آموزش و پارامترهای خود راضی هستید و مرحلۀ ارزیابی را بهدرستی گذراندید، وقت آن است که در نهایت از مدل خود برای انجام کاری واقعی استفاده کنید!
مرحلۀ هفتم: پیشبینی
در این مرحله بالاخره میتوان به سؤالی که در ابتدا برایمان وجود داشت پاسخ دهیم. وقتی معادلۀ خط نهایی با کشف m و b به دست آمد، میتوان هر x که در سازمان به آن برخوردیم را به سیستم وارد کنیم و y متناظر با آن را پیشبینی کنیم.
همانطور که تاکنون متوجه شدیم، سه عنصر اصلی سیستم یادگیری ماشین عبارتاند از: مدل، پارامترها و یادگیرنده (Learner). اگر موافقید یک بار دیگر مفهوم هر یک را در جملهای ساده یادآوری کنیم.
- مدل سیستمی است که پیشبینی میکند.
- پارامترها عواملی هستند که مدل آنها برای پیشبینی در نظر میگیرد.
- یادگیرنده پارامترها و مدل را تنظیم میکند تا پیشبینیها را با نتایج واقعی هماهنگ کند.
انواع مختلف ماشین لرنینگ چیست؟
یادگیری ماشین کلاسیک، اغلب بر اساس نحوۀ یادگیری الگوریتم در پیشبینی دقیقتر طبقهبندی میشود. در اینجا چهار رویکرد اساسی وجود دارد که عبارتاند از:
- یادگیری تحت نظارت (Supervised Learning)
- یادگیری بدون نظارت (Unsupervised Learning)
- یادگیری نیمه نظارتشده (Semi-Supervised Learning)
- یادگیری تقویتی (Reinforcement Learning)
در ادامه هر یک از این انواع را به طور مختصر بررسی خواهیم کرد.
یادگیری ماشین تحت نظارت
در این نوع یادگیری، دانشمندان داده یا همان Data Scientists ها، الگوریتمهایی با دادههای برچسبگذاری شده به یک ماشین میدهند. یعنی دادهها از ابتدا با جوابهای صحیح یا همان نتیجه برچسبگذاری شدهاند و ماشین با استناد به این دادههای قبلی، در صورت ورود دادههای جدید در مورد آنها تصمیمگیری میکند.
اکثر فرایندهای ML از یادگیری تحت نظارت استفاده میکنند. در این حالت سیستم تلاش میکند تا الگوها یا مدلها را بر اساس مثالها و نمونههای داده شده به آن بیاموزد.
برای مثال شما ممکن است چندین نمونۀ مختلف از عبارت دستنویس «سلام» را به سیستم بدهید و هر یک از نمونهها را با برچسب عبارت تایپی «سلام» برچسبگذاری کنید. حال یک عبارت دستنویس جدید از «سلام» به سیستم میدهید و ازآنجاییکه ماشین با مجموعه دادههای پیشین شما بهصورت تصویری شرطی شده است، میتواند آن را بهصورت عبارت تایپی «سلام» ارائه دهد.
به یاد داشته باشید که هر چه مجموعه دادههای برچسب گذاری شده که در اختیار ماشین قرار میدهید، بزرگتر باشد، ماشین بهتر میتواند در مورد موضوع یاد بگیرد و پیشبینیهای دقیقتری ارائه دهد. از جمله الگوریتمهای یادگیری تحت نظارت میتوان Regression،Decision Tree،Random Forest ، KNN و Logistic Regression را نام برد.
یادگیری ماشین بدون نظارت
این نوع یادگیری ماشین شامل الگوریتمهایی است که با دادههای بدون برچسب به ماشین آموزش میدهند. اینجا به الگوریتم یادگیری نمیگوییم هر یک از دادهها نمایانگر چه چیزی هستند؛ بلکه خود الگوریتم با جستجوی هرگونه ارتباط معنیدار مجموعه دادهها را اسکن میکند. یعنی در یادگیری بدون نظارت، ما فقط متغیرهای ورودی (X) را داریم و هیچ متغیر خروجی (Y) وجود ندارد. اینجا سیستم ممکن است به دادهها به دو صورت کلی یا گروهی نگاه کند.
در حالت کلی که انجمنی نیز نامیده میشود، هدف کشف قانونهایی است که بخش بزرگی از دادهها را توصیف کند. مثلاً سیستم در نهایت با بررسی مجموعه دادههای ورودی اعلام میکند: «هر شخصی که کالای A را خریداری کند، به خرید کالای B نیز تمایل دارد.»
اما در حالت گروهی یا خوشهای سیستم میخواهد گروههای ذاتی یا همان دادههایی که ذاتاً در یک گروه خاص میگنجند را کشف کند. مثلاً سیستم در نهایت با بررسی مجموعه دادههای ورودی، گروهبندی مشتریان را بر اساس رفتار خرید آنها اعلام میکند.
بدیهی است که انتخاب میان این دو حالت بسته به نیاز و هدف ما میتواند توسط برنامهنویس انجام گیرد. Apriori و K-means مثالهای متداول از الگوریتمهای یادگیری نظارت نشده هستند.
یادگیری ماشین نیمه نظارت شده
این رویکرد برای یادگیری ماشین شامل ترکیبی از دو نوع قبلی است. اینجا دانشمندان داده ممکن است از الگوریتمی استفاده کنند که دادهها دارای برچسب باشند و برخی نباشند. حال مدل آزاد است که دادهها را به صورت ترجیحی میان برچسبدار و غیر برچسبدار کاوش کند و درک خاص خود را از مجموعه دادهها توسعه دهد.
یادگیری نیمه نظارت شده زمانی مفید است که هزینۀ مربوط به برچسب زدن آنقدر زیاد باشد که امکان آموزش کامل ماشین توسط کاربر وجود نداشته باشد.
یادگیری ماشین تقویتی
اجازه دهید این روش یادگیری را با یک مثال توضیح دهیم. فرض کنیم ماشین قرار است یک بازی انجام دهد. هر بار که ماشین برندۀ بازی شود، میتواند از نتیجۀ کار برای "تقویت" حرکات آیندۀ خود در حین بازی استفاده کند.
بدیهی است که اگر ماشین فقط یک یا دو بار بازی را انجام دهد، یادگیری تقویتی خیلی به توانایی انجام بازی کمکی نخواهد کرد. اما وقتی هزاران بار بازی تکرار شود، ماشین کمکم میتواند نوعی استراتژی پیروزی را برای خود شکل دهد.
در این نحوۀ یادگیری، الگوریتم با واردشدن به چرخۀ آزمون و خطا یاد میگیرد که در مواقع مشخص، تصمیمات مشخصی بگیرد. به این ترتیب با توجه به تصمیمات و تجربیات پیشین میتواند پیشبینیها و تصمیمات بعدی خود را اصلاح کند و به طور مداوم در حال آموختن باشد.
دانشمندان داده معمولاً از یادگیری تقویتی برای آموزش ماشین به منظور تکمیل فرایندهای چند مرحلهای که قوانین مشخصی برای آن وجود دارد، استفاده میکنند. در این روش یادگیری نیز مانند نوع بدون نظارت، الگوریتم بهتنهایی تصمیم میگیرد که در طول مسیر چه اقداماتی باید انجام دهد. Markov Decision Process یکی از الگوریتمهای متداول یادگیری تقویتی است.
پایتون در انتخاب بین برنامهنویسی شیءگرا یا برنامهنویسی Scripting انعطافپذیری بالایی را ارائه میدهد. همچنین در این بستر نیازی به کامپایل مجدد کد نیست. توسعهدهندگان میتوانند هرگونه تغییر را پیادهسازی کرده و نتایج را فوراً مشاهده کنند. برای دستیابی به عملکرد و نتایج دلخواه میتوانید از Python به همراه زبانهای دیگر نیز استفاده کنید.
و در آخر اینکه پایتون یک زبان برنامهنویسی همهکاره است که میتواند روی هر پلتفرمی از جمله Windows ، MacOS ، Linux ، Unix و... اجرا شود. البته در حین مهاجرت از یک پلتفرم به پلتفرم دیگر، کدی که نوشتهاید نیاز به تعدیل و تغییرات جزئی دارد و سپس آمادۀ کار بر روی پلتفرم جدید خواهد بود.
کدام زبان برای Machine Learning بهتر است؟
پایتون (Python) به دلیل مزایای مختلفی که در ادامه ذکر میکنیم، بهترین زبان برنامهنویسی برای برنامههای یادگیری ماشین است. سایر زبانهای برنامهنویسی که میتوانند برای برنامههای یادگیری ماشین استفاده شوند، عبارتاند از:
R، C ++، JavaScript، جاوا، C#، جولیا، Shell، TypeScript، Scala
اما چرا ما پایتون را پیشنهاد میدهیم؟
پایتون به دلیل خوانایی و پیچیدگی نسبتاً پایین در مقایسه با سایر زبانهای برنامهنویسی مشهور است. برنامههای ML شامل مفاهیم پیچیدهای مانند حساب و جبر خطی هستند که پیادهسازی آنها تلاش و زمان زیادی میطلبد.
اینجا پایتون با قابلیت پیادهسازی سریع (Quick Implementation) وقتی نیاز به تأیید یک ایده باشد، به کمک مهندسین ML میآید و بار زحمات را تا حدود زیادی کاهش می دهد.
یکی دیگر از مزایای استفاده از پایتون در یادگیری ماشین، کتابخانههای از پیش ساخته شده است. بستههای مختلفی برای انواع مختلف برنامهها وجود دارد که برخی از مهمترینها را در ادامه ذکر میکنیم:
- هنگام کار با تصاویر از Numpy ، OpenCV و Scikit استفاده میشود.
- هنگام کار با متن از NLTK همراه با Numpy و Scikit استفاده میشود.
- برای کاربردهای صوتی Librosa بهترین گزینه است.
- برای نمایش دادهها میتوان Matplotlib ، Seaborn و Scikit را به کار برد.
- TensorFlow و Pytorch برای برنامههای آموزشی عمیق استفاده میشوند.
- Scipy برای محاسبات علمی
- Django برای ادغام برنامههای وب
- Pandas برای ساختار دادهها و تجزیهوتحلیل سطح بالا
پایتون در انتخاب بین برنامهنویسی شیءگرا یا برنامهنویسی Scripting انعطافپذیری بالایی را ارائه میدهد. همچنین در این بستر نیازی به کامپایل مجدد کد نیست. توسعهدهندگان میتوانند هرگونه تغییر را پیادهسازی کرده و نتایج را فوراً مشاهده کنند. برای دستیابی به عملکرد و نتایج دلخواه میتوانید از Python به همراه زبانهای دیگر نیز استفاده کنید.
و در آخر اینکه پایتون یک زبان برنامهنویسی همهکاره است که میتواند روی هر پلتفرمی از جمله Windows ، MacOS ، Linux ، Unix و... اجرا شود. البته در حین مهاجرت از یک پلتفرم به پلتفرم دیگر، کدی که نوشتهاید نیاز به تعدیل و تغییرات جزئی دارد و سپس آمادۀ کار بر روی پلتفرم جدید خواهد بود.

یادگیری ماشین چه کاربردهایی دارد؟
امروزه از یادگیری ماشین در طیف گستردهای از کاربردها استفاده میشود. شاید یکی از مشهورترین نمونههای در حال اجرا، موتور توصیه (Recommendation Engine) است که به خوراک خبری فیسبوک (Facebook's News Feed) قدرت میبخشد.
اینجا فیسبوک از یادگیری ماشین برای شخصیسازی نحوۀ چینش فید هر یک از اعضا استفاده میکند. اگر یک کاربر مکرراً برای مشاهدۀ گروه خاصی از پستها متوقف شود، موتور توصیه شروع به نمایش بیشتر فعالیتهای آن گروه خاص در فید میکند؛ یعنی در پشت صحنه موتور در حال تلاش برای تقویت الگوهای شناخته شده در رفتار آنلاین اعضا است. در صورتی که اعضا الگوهای خود را تغییر دهند و در هفتههای آینده پستهای آن گروه را نخوانند، فید مطابق این رفتار جدید تنظیم میشود.
شاید مشهورترین مثالی که بعد از این کاربرد بتوان ذکر کرد، سیستم مدیریت ارتباط با مشتری (Customer Relationship Management) یا بهاختصار CRM باشد.
CRM میتواند از مدلهای یادگیری ماشین برای تجزیه و تحلیل ایمیل استفاده کرده و اعضای تیم فروش را ترغیب کند تا ابتدا به مهمترین پیامها پاسخ دهند. سیستمهای پیشرفتهتر حتی میتوانند پاسخهای مناسب را توصیه کنند.
اما کاربردهای ML تنها به این موارد محدود نمیشوند. دنیایی از کاربردها برای این تکنولوژی وجود دارد که در ادامه بخشی از آنها را در دستههایی جداگانه ذکر میکنیم.
تشخیص چهره/تشخیص تصویر
شاید بتوان گفت رایجترین و مشهورترین کاربرد یادگیری ماشین، تشخیص چهره است و سادهترین مثال این کاربرد تشخیص چهره در موبایلهای هوشمند امروزی است. البته موارد بسیار زیادی برای تشخیص چهره وجود دارد که بیشتر برای اهداف امنیتی مانند شناسایی مجرمان، جستجوی افراد مفقود و پزشکی قانونی استفاده میشوند. البته بازاریابی هوشمند، تشخیص بیماری، پیگیری حضور در مدارس و ادارات و امور اینچنینی نیز از فناوریهای تشخیص تصویر بهره میجویند.

تشخیص خودکار گفتار
تشخیص خودکار گفتار (Automatic Speech Recognition) را ممکن است با نام مخفف آن یعنی ASR مشاهده کرده باشید. این فناوری برای تبدیل گفتار به متن دیجیتال استفاده میشود. از کاربردهای آن میتوان به احراز هویت کاربران بر اساس صدای آنها و انجام وظایف دیجیتالی بر اساس ورودی صدای انسان اشاره کرد.
خدمات مالی
بانکها و سایر مشاغل فعال در خدمات مالی از ماشین لرنینگ برای دو هدف اصلی استفاده میکنند: شناسایی بینش یا نگرش (Insight) مهمی در دادهها و جلوگیری از تقلب. نگرشها میتوانند فرصتهای سرمایهگذاری را شناسایی کنند و به سرمایهگذاران بانکی بگویند چه زمانی برای تجارت بهترین موقع است. دادهکاوی یا Data Mining که یکی از زیرمجموعههای ML است، همچنین میتواند مشتریان با پروفایلهای پرخطر را شناسایی کند یا از نظارت سایبری برای تعیین علائم هشداردهندۀ کلاهبرداری استفاده کند.
امور دولتی
آژانسهای دولتی مانند ایمنی عمومی و خدمات عمومی به Machine Learning نیازی مبرم دارند، چرا که منابع متعددی از دادهها دارند که دارای الگو هستند و اغلب وظایف خدماتی نیز در این حوزهها اموری ثابت و یکسان هستند. برای مثال یادگیری ماشین اینجا میتواند در به حداقل رساندن سرقت هویت تأثیر به سزایی داشته باشد.
خردهفروشی
وبسایتهایی که بر اساس خریدهای قبلی شما، مواردی را که ممکن است دوست داشته باشید، به شما توصیه می کنند، از یادگیری ماشین برای تجزیه و تحلیل سابقۀ خرید شما استفاده میکنند. این خرده فروشان برای جمعآوری دادههای تجاری و سپس آنالیز و استفاده از آنها برای شخصیسازی تجربه خرید، تا حدود زیادی به Machine Learning وابسته هستند.
امروزه اجرای کمپینهای بازاریابی، بهینهسازی قیمت، برنامهریزی برای واردات یا صادرات کالا و تشخیص نگرش مشتری با استفاده از هوش مصنوعی بسیار سادهتر و دقیقتر شدهاند.

ماشین لرنینگ چه آیندهای خواهد داشت؟
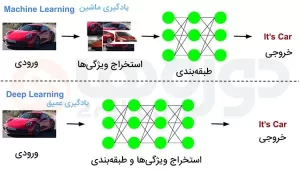
اگر چه الگوریتمهای یادگیری ماشین تنها برای چندین دهه مهمان ما بودهاند، اما امروزه با افزایش استقبال بشر از هوش مصنوعی به محبوبیت بیشتری دست یافتهاند. در حال حاضر در اکثر غولهای ارتباطی و تکنولوژی جهان مدلهای یادگیری عمیق (Deep Learning) پیشرفتهترین کاربردهای مربوط به هوش مصنوعی را تقویت میکنند؛ بنابراین میتوان حدس زد یادگیری عمیق در سالهای آینده به یکی از حوزههای پرکاربرد فناوری اطلاعات تبدیل شود.
یادگیری عمیق همان یادگیری ماشین است که روی اصول کارکرد استروئیدها استوار است؛ در واقع یادگیری عمیق از تکنیکهای منحصر به فردی استفاده میکند که به ماشینها توانایی پیداکردن و تقویت حتی کوچکترین الگوها در میان دادهها را میدهد. این تکنیک را شبکه عصبی عمیق (Deep Neural Network) نیز مینامند.
این نوع هوش مصنوعی دارای لایههای متعدد از گرههای محاسباتی ساده است که با هم کار میکنند و دادهها را به هم میریزند تا نتیجۀ نهایی را در قالب یک مدل پیشبینی ارائه دهند، به دلیل همین خاصیت لایهای بودن، واژۀ عمیق به آن اطلاق میشود.
طی چند سال آینده، پلتفرمهای مبتنی بر یادگیری ماشین از جمله رقابتیترین حوزههای فناوری سازمانی خواهند بود. حتی همین امروز هم اکثر فروشندگان عمده از جمله آمازون، گوگل، مایکروسافت، IBM و ... برای جمعآوری، طبقهبندی، مدلسازی و استقرار دادهها از الگوریتمهای یادگیری ماشین استفاده میکنند.
با این حال هنوز هم محققان در حال بررسی راههایی برای انعطافپذیری بیشتر مدلهای ML هستند. به این ترتیب که ماشین با استناد به فرایندهای آموخته شده در یک وظیفه، بتواند وظایف جدید آینده را نیز پاسخگو باشد و به عبارتی خود را آداپته کند.
جمعبندی
در این مقاله سعی کردیم با زبانی ساده با یادگیری ماشین (ML)، انواع و کاربردهای آن آشنا شویم. دیدیم که به طورکلی علم و تکنولوژی ماشین لرنینگ شامل مطالعۀ الگوریتمهایی است که میتوانند یک یا چند مدل را بر اساس دادههای ورودی یا دادههای آموزشی میسازند تا بتوانند بر اساس آنها پیشبینی یا تصمیمگیری کنند. امروزه یادگیری ماشین در طیف گستردهای از کاربردها مانند بازاریابی دیجیتال، پزشکی، پلتفرمهای اجتماعی، تشخیص تصویر، گفتار و ... کاربرد دارد.
منابعwww.mygreatlearning.com www.searchenterpriseai.techtarget.com www.technologyreview.com




